이 글은 Cover사의 AIこより爆誕!?の裏側 를 번역한 글입니다. 현재 진행하고 있는 프로젝트에 적용할 점이 있을 것 같아 개인용으로 작업하였습니다.
콘코요~🧪
커버 주식회사 CTO실 엔지니어인 A입니다.
커버 주식회사에는 2023년 4월에 신졸(*신입)으로 입사해, 제1회 COVER Tech를 작성하신 K씨의 밑에서 탤런트분들이 매일 YouTube 방송 등에서 사용하는 홀로라이브 어플리케이션 개발에 참여하고 있습니다.
또, 최근 수 개월간 위와 병행하여 AI코요리 시스템의 개발을 담당하였습니다.
이 기사에서는 개발한 시스템의 개요에 대해 소개합니다.
목차
개발 경위
AI코요리 시스템의 개발을 하게 된 경위에 대해서.
먼저 사내에 생성AI의 가능성이나 관련기술의 검토를 하고 싶다는 필요가 있었습니다. 거기에, 코요리씨로부터 본인의 AI를 만들고 싶다는 요청을 받았기에 그것이 계기가 되어, 코요리씨의 전면적인 협력 아래 AI코요리 시스템의 개발이 시작되었습니다.
시스템 개요
이번에 개발한 것은, AI시스템으로의 입출력을 조작하여 방송 화면에 송출되게 하는 프론트 어플리케이션과, 각종 외부 API와의 통신이나 내부 데이터의 처리를 하는 서버 시스템으로 나뉘어 있습니다.
시스템 전체는 아래 그림처럼 되어있습니다.
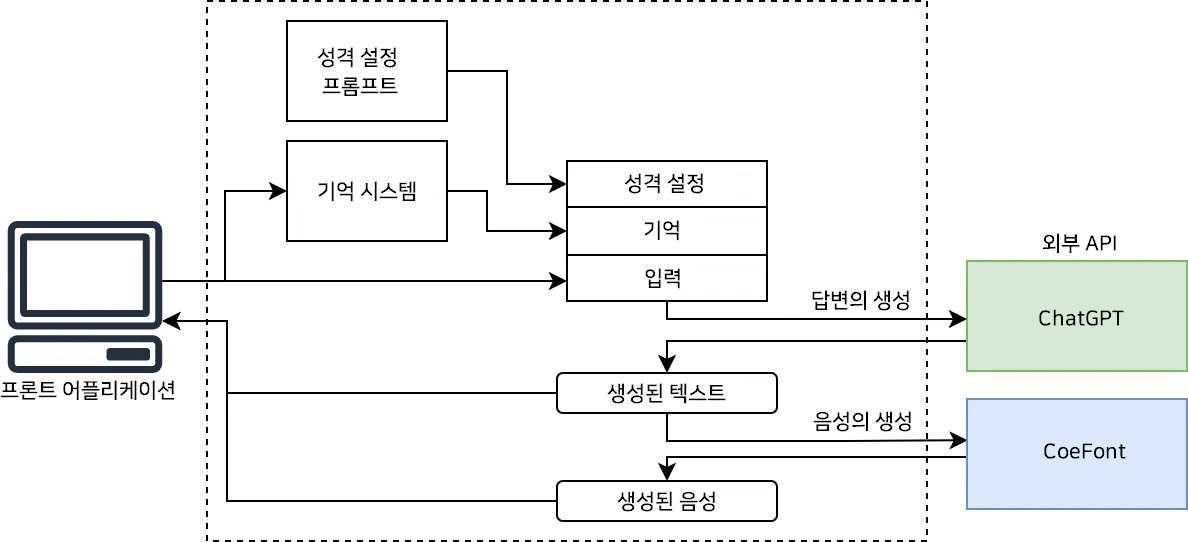
프론트 어플리케이션
프론트 어플리케이션은 크게 1. 입력 2. 답변의 체크 3. 답변의 표시 세 개의 처리 플로우가 있습니다.
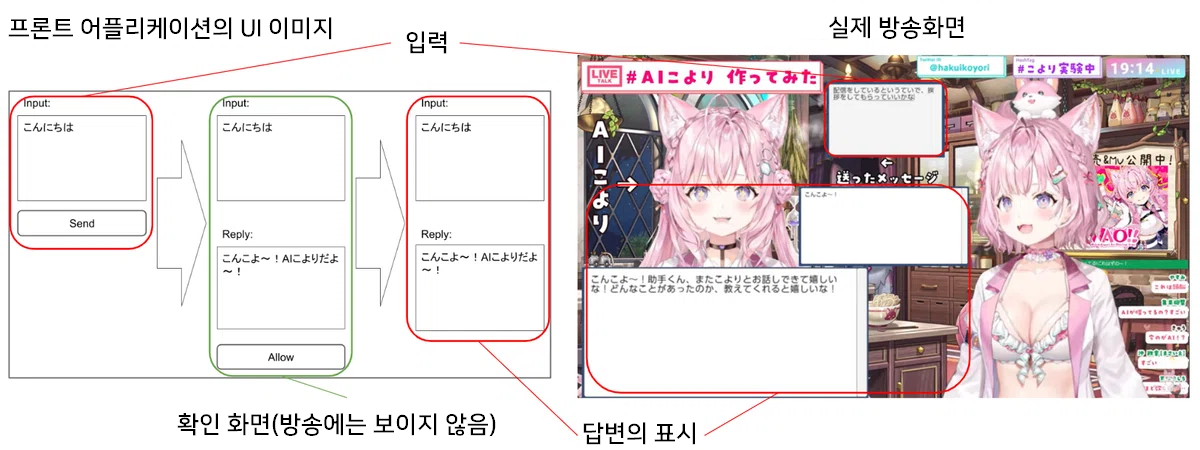
- 입력
현재 프론트 어플리케이션은 텍스트 입력과 음성 입력에 대응하고 있습니다. 음성 입력 시 음성의 필사는 OpenAI API의 Whisper를 이용하고 있습니다. - 답변의 체크
입력에 대한 AI의 답변이 돌아오면, 그 내용을 체크합니다. 이번에 이용하고 있는 ChatGPT는 비윤리적인 발언을 하지 않도록 조정12되어 있으나, 절대로 안심할 수 있는 것은 아니기에 방송에 내보내기에 부적절한 내용이 포함되어 있을 가능성이 있습니다. 이를 위해 프론트 어플리케이션 위에서 AI 답변 내용의 확인 화면과 실제로 방송에 내보내는 화면을 나누어 놓아, 한번 내용을 확인한 뒤에 방송 화면에 표시한다는(Human in the loop3) 플로우를 구축하고 있습니다. - 답변의 표시
AI의 낭독 음성의 재생이나 텍스트 표시 애니메이션을 컨트롤합니다.
이 외에도, 코요리씨의 방송 기획의 니즈를 반영하여 각종 기능이 실장되어 있습니다.
서버 시스템
서버 시스템에서는 답변 텍스트의 생성・답변 낭독 음성의 생성을 수행하고 있습니다.
답변 텍스트의 생성
AI의 답변 생성은 ChatGPT(gpt-3.5-turbo)를 이용하고 있습니다.
https://platform.openai.com/docs/guides/text?api-mode=responses
ChatGPT로의 입력은 ■성격 설정 ■대화의 기억 ■현재의 입력으로 구성되어 있습니다.
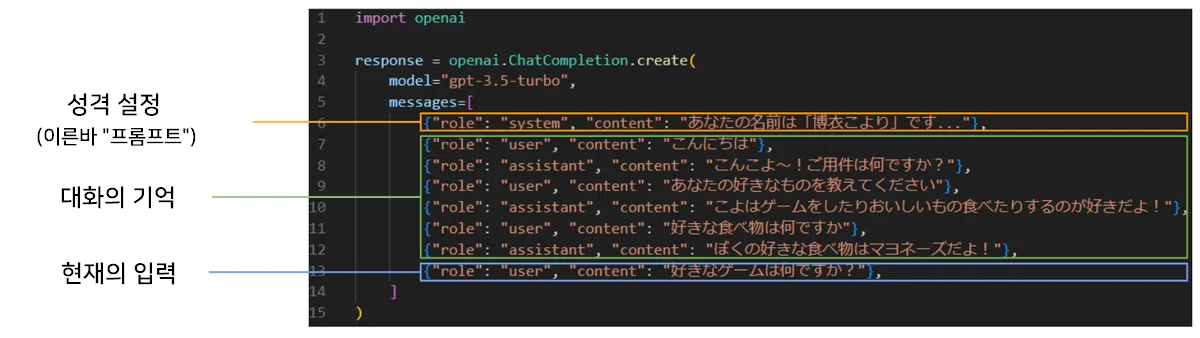
■성격 설정
성격 설정의 프롬프트는 코요리씨의 감수 하에 작성되었습니다.
ChatGPT의 캐릭터화나 성격 설정의 식견에 대해서는 소개하고 있는 기사가 많기 때문에, 기본적인 부분은 본 기사에서는 생략합니다. 한 가지, 어조의 변환 동작에 대해 설명하겠습니다.
코요리씨로부터의 요청으로, 어조를 정중한 어조와 반말 어조로 바꾸고 싶다는 것이 있었습니다. 입력부터 “반말로 말해줘” “경어로 말해줘” 등으로 지시하는 것을 통해, 어조를 변환한다는 동작입니다.
이것에 대해서, 일단
- 프롬프트에 의한 지시
- 예문 제시
에 의한 동작의 설정을 구성하였습니다. 이하에 나타나있는 프롬프트 예시는 실제로 사용되고 있는 것과 다릅니다.
character = 博衣こより
{Character}'s tone: {
You speak in either a casual or honorific tone.
You switch your tone if you are requested.
Examples of honorific tone:
...
Examples of casual tone:
...
}
Examples of dialogue: {
Example of dialogue 1:
User: こんにちは
Character: こんこよ~!ご用件は何ですか?
User: ため口で話してください
Character: わかった!こんな感じで話すね!
Example of dialogue 2:
...
}
하지만, 이 방법만으로는 어조가 안정되지 않거나, 지시대로 어조가 바뀌지 않거나 하는 동작이 나타났습니다.
이에 따라, 추가로 출력의 어조에 대해 라벨을 붙이는 것처럼 지시를 추가하였습니다. 출력을 dictionary 형태로 바꾸어, 답변의 어조(tone)이 반말일 경우 “casual”, 경어일 경우 “honorific"이라고 라벨을 붙이도록 지시하였습니다.
character = 博衣こより
{Character}'s tone: {
You can take tone value as "honorific" or "casual".
Your default tone is "honorific".
You switch your tone if you are requested.
You must indicate your current tone, "honorific" or "casual", in your output.
Examples of "honorific":
...
Examples of "casual":
...
}
Examples of dialogue: {
You must output your reply and your current tone in dictionary format, like {"reply": "Your reply here", "tone": "honorific" or "casual"}.
Example of dialogue 1:
User: こんにちは
Character: {"reply": "こんこよ~!ご用件は何ですか?", "tone": "honorific"}
User: ため口で話してください
Character: {"reply": "わかった!こんな感じで話すね!", "tone": "casual"}
Example of dialogue 2:
...
}
결과, gpt-4에 들어서는 안정적으로 어조를 바꾸는 것이 가능해져, gpt-3.5에서도 어느 정도 동작하는 것을 확인하였습니다.
■대화의 기억
간단하게 실장되는 것이라면, 최근 $N$건의 입출력을 보존하는 방법을 생각할 수 있습니다만, 이 방법으로는 그 이상의 대화 정보가 소실되어버립니다. 이에 따라, 본 시스템에서는 아래의 논문4을 참고로 기억 시스템을 구축하였습니다.
https://arxiv.org/abs/2304.03442
이번에 실장된 기억 시스템은, 모든 기억(과거의 대화)으로부터 관련도가 높은 기억만을 추출하여 ChatGPT로의 입력에 포함시킨다는 방식을 취하고 있습니다.
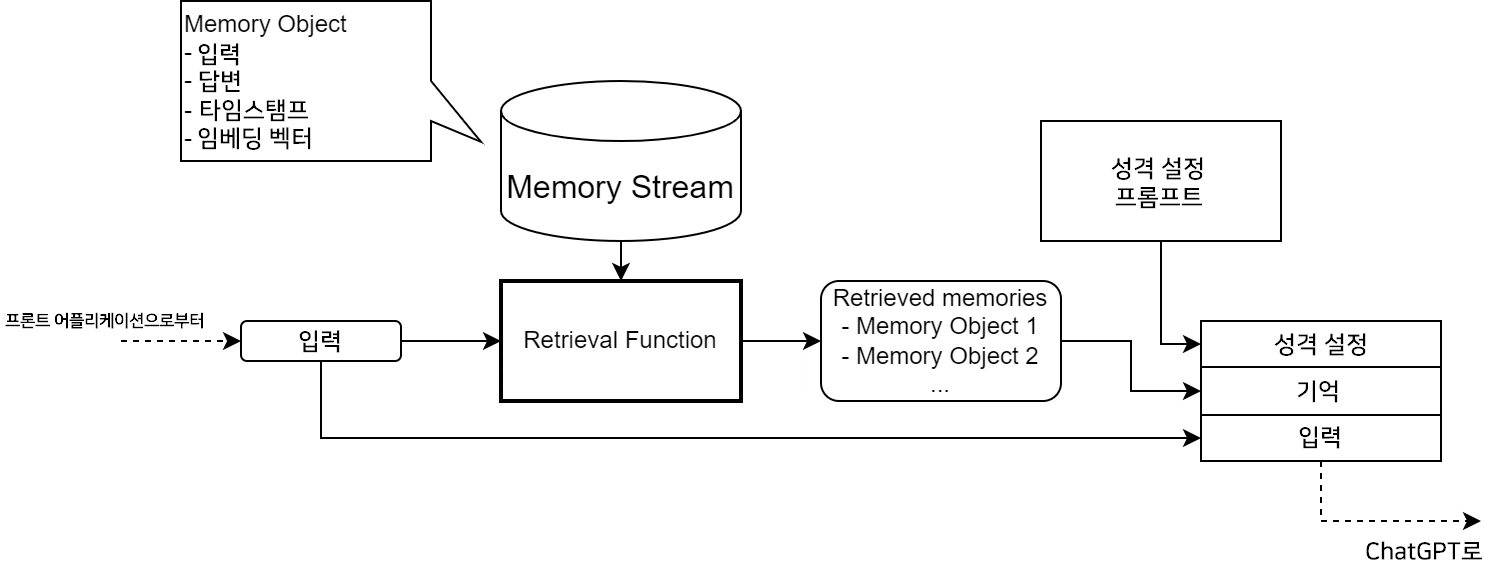
- Memory Object: 하나하나의 대화의 기억
- Memory Stream: 저장되어 있는 모든 Memory Object
Retrieval Function에 의해, 입력과 Memory Stream의 각각의 기억마다 Retrieval Score를 산출하여 스코어 상위 $N$건의 기억을 Retrieved memories로서 ChatGPT로의 입력 프롬프트에 포함시킵니다.
$i$번째의 기억의 Retrieval Score는 아래 수식으로 산출되어, 입력과 Memory Stream 내의 각각의 기억과의 관련 정도를 나타냅니다.
$$Recency = e^{-\alpha(t_I-t_{M_i})}$$
$$Relevance = \frac{E_i \cdot E_{M_i}}{||E_I||||E_{M_i}||}$$
여기서, $w_1$, $w_2$는 가중치, $t_I$는 입력의 시각, $t_{M_i}$는 $i$번째 기억의 시각, $E_I$는 입력의 임베팅 벡터, $E_{M_i}$는 $i$번째 기억의 임베딩 벡터, ⋅는 점곱(내적)입니다.
또, 이번에는 $\alpha = 2.0 \times 10^{-4}$ (1시간에 약 반절로 감소)로 두고 있습니다.
임베딩 벡터란 문장을 $1,536$차원의 수치 벡터로 변환한 것으로, 문장의 특징을 표현하고 있습니다. 벡터 간 거리는 문장 사이의 관련 정도를 나타냅니다.5
본 시스템에서는 OpenAI API의 Embeddings를 사용해 입력과 답변을 이어붙인 문장의 임베딩 벡터를 얻어 이것을 Memory Object의 임베딩 벡터로 사용하고 있습니다.
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
위의 식은 아래를 표현하고 있습니다.
- Recency
- 입력을 받은 시각과 각각의 Memory object의 시각의 차에 따라 지수함수로 감소하는 값
- 최근의 Memory일 수록 Recency 값이 커집니다.
- Relevance
- 입력의 임베딩과 각각의 Memory의 임베딩의 코사인 유사도
- 이 값은 입력과 각각의 Memory의 유사도를 나타내고, 유사도가 높을수록 Relevance의 값이 커집니다.
시스템 가동 초기에는 이 알고리즘을 통해 retrive된 20건의 Memory object를 ChatGPT로의 입력에 포함시켰습니다. 하지만 실제 대화를 하는 중 대화 주제가 왔다갔다 하는 등 예상치 못한 동작이 보였기 때문에 현재는,
- 최근 10건의 Memory object를 입력 프롬프트에 포함시킨다
- 그 이상의 Memory object에서 Retrieval score의 상위 10건을 프롬프트에 포함시킨다
라는 알고리즘으로 되어 있습니다.
답변 낭독 음성의 생성
낭독 AI 모델의 학습 및 이용은 CoeFont의 서비스를 이용하고 있습니다.
https://coefont.cloud/coefonts
CoeFont를 차용한 이유로써,
- API로의 이용이 가능
- 학습 데이터의 녹음이 브라우저상에서 가능 이라는 점이 있었습니다.
특히 학습 데이터 녹음이 간편하다는 점이 커서, 탤런트의 활동에 압박을 주지 않고, 자택에서 빈 시간에 녹음을 수행하는 것이 가능하였습니다. 이번에는 학습 데이터로써 $3,000$자의 문장을 코요리씨가 녹음해 주셨습니다. (정말로 수고 많으셨습니다…!)
본 시스템에서는, CoeFont가 제공하는 API로 낭독할 텍스트를 보내, 생성된 음성 데이터를 프론트 어플리케이션에서 재생하고 있습니다.
정리
이번에는 AI코요리 시스템의 전체적인 개요를 소개하였습니다. 이번에 제가 작성한 것은, 기존 서비스나 기술을 이어붙인 극히 간단한 시스템에 지나지 않습니다. 이것을 활용하여 재미있는 컨텐츠로 승화할 수 있었던 것은, 코요리씨를 시작으로 한 탤런트 분들의 아이디어와 창의성 덕분입니다. 저희는 이후에도 탤런트 분들의 아이디어를 기술로 서포트하고, 새로운 기술에 대한 연구를 계속하는 것으로써 팬 분들에게 즐거움을 선사하는 것을 목표로 개발에 임할 것입니다.
관련된 서비스의 개발을 기획하던 중, 좋은 기사를 발견하여 번역해보았습니다. 많은 도움이 되었으면 좋겠습니다.